
Image Classification of Dogs and Cats
In this tutorial, we’ll be discussing how to make a model to classify images of dogs and cats using Tensorflow and Keras.
Initialization
First we’ll load in the following libraries:
import tensorflow as tf
import os
from tensorflow.keras import utils
from tensorflow.keras import models, layers, losses
Now lets load in our data of labeled images of cats and dogs which is provided to us already by the TensorFlow team.
# location of data
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
# download the data and extract it
path_to_zip = utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
# construct paths
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
# parameters for datasets
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
# construct train and validation datasets
train_dataset = utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
# construct the test dataset by taking every 5th observation out of the validation dataset
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
Now paste in the following code block which will help us rapidly read in the data:
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Analyzing our dataset
Lets now create a function to visualize the images of our dogs and cats. This function will show a 2 x 3 grid of three random cats in the first row and three random dogs in the second row.
from matplotlib import pyplot as plt
def visualization():
class_names = ['cats', 'dogs']
fig, ax = plt.subplots(2,3, figsize=(8,6))
for images, labels in train_dataset.take(1):
i = 0
#iterates over one batch of 32 images
for j in range(32):
row = i // 3
col = i % 3
#checking to see if the label is cat while we still haven't printed 3 cats yet
if (class_names[labels[j]] == 'cats') and (i < 3):
ax[row,col].imshow(images[j].numpy().astype('uint8'))
ax[row,col].set_title(class_names[labels[j]])
i += 1
#checking to see if the label is a dog once we already printed 3 cats
if (class_names[labels[j]] == 'dogs') and (i > 2):
ax[row,col].imshow(images[j].numpy().astype("uint8"))
ax[row,col].set_title(class_names[labels[j]])
i += 1
ax[row,col].axis("off")
if i == 6:
break
visualization()

Now lets compute the number of cat and dog images in our data:
labels_iterator= train_dataset.unbatch().map(lambda image, label: label).as_numpy_iterator()
number_of_cats = 0
number_of_dogs = 0
for label in labels_iterator:
if label == 0:
number_of_cats += 1
else:
number_of_dogs += 1
print(f'There are {number_of_cats} images of cats and {number_of_dogs} images of dogs.')
There are 1000 images of cats and 1000 images of dogs.
The baseline machine learning model is a model that always guesses the most frequent label. In our case since they are an equal number of cats and dogs, the baseline model will have a 50% accuracy.
Creating our first model
Now lets make our first machine learning model for image classification. We will be alternating between Conv2D and MaxPooling2D layers. The Dropout layers will provide some randomoness and Flatten will go from 2D to 1D since our Dense layer will need to be 1D. After creating our model we’ll compile it and then show a nice visualization plotting the accuracy of our training and validation scores.
model1 = models.Sequential([
layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Dropout(0.2),
layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Dropout(0.2),
layers.Conv2D(filters = 64, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Flatten(),
layers.Dense(64, activation = 'relu'),
layers.Dense(2)
])
model1.compile(loss=losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=['accuracy'])
history = model1.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 6s 86ms/step - loss: 43.5111 - accuracy: 0.5235 - val_loss: 0.6869 - val_accuracy: 0.5421
Epoch 2/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6849 - accuracy: 0.5510 - val_loss: 0.6931 - val_accuracy: 0.5297
Epoch 3/20
63/63 [==============================] - 6s 94ms/step - loss: 0.6721 - accuracy: 0.5710 - val_loss: 0.6799 - val_accuracy: 0.5495
Epoch 4/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6658 - accuracy: 0.5850 - val_loss: 0.6705 - val_accuracy: 0.5891
Epoch 5/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6312 - accuracy: 0.6320 - val_loss: 0.6677 - val_accuracy: 0.5829
Epoch 6/20
63/63 [==============================] - 6s 85ms/step - loss: 0.6162 - accuracy: 0.6400 - val_loss: 0.6455 - val_accuracy: 0.6473
Epoch 7/20
63/63 [==============================] - 5s 81ms/step - loss: 0.5962 - accuracy: 0.6550 - val_loss: 0.7105 - val_accuracy: 0.5681
Epoch 8/20
63/63 [==============================] - 6s 85ms/step - loss: 0.5609 - accuracy: 0.6975 - val_loss: 0.6671 - val_accuracy: 0.6163
Epoch 9/20
63/63 [==============================] - 6s 84ms/step - loss: 0.5091 - accuracy: 0.7290 - val_loss: 0.6914 - val_accuracy: 0.6089
Epoch 10/20
63/63 [==============================] - 6s 84ms/step - loss: 0.4859 - accuracy: 0.7570 - val_loss: 0.7458 - val_accuracy: 0.5953
Epoch 11/20
63/63 [==============================] - 6s 86ms/step - loss: 0.4462 - accuracy: 0.7900 - val_loss: 0.9254 - val_accuracy: 0.5978
Epoch 12/20
63/63 [==============================] - 6s 86ms/step - loss: 0.3996 - accuracy: 0.7910 - val_loss: 0.8203 - val_accuracy: 0.6188
Epoch 13/20
63/63 [==============================] - 6s 84ms/step - loss: 0.3526 - accuracy: 0.8325 - val_loss: 0.9277 - val_accuracy: 0.6077
Epoch 14/20
63/63 [==============================] - 6s 84ms/step - loss: 0.3260 - accuracy: 0.8515 - val_loss: 1.2051 - val_accuracy: 0.6200
Epoch 15/20
63/63 [==============================] - 6s 85ms/step - loss: 0.3318 - accuracy: 0.8555 - val_loss: 1.2161 - val_accuracy: 0.5829
Epoch 16/20
63/63 [==============================] - 6s 84ms/step - loss: 0.2673 - accuracy: 0.8775 - val_loss: 1.3145 - val_accuracy: 0.5792
Epoch 17/20
63/63 [==============================] - 6s 84ms/step - loss: 0.2316 - accuracy: 0.8995 - val_loss: 1.2198 - val_accuracy: 0.6114
Epoch 18/20
63/63 [==============================] - 6s 84ms/step - loss: 0.2146 - accuracy: 0.9110 - val_loss: 1.2282 - val_accuracy: 0.6064
Epoch 19/20
63/63 [==============================] - 5s 81ms/step - loss: 0.1787 - accuracy: 0.9305 - val_loss: 1.4473 - val_accuracy: 0.6064
Epoch 20/20
63/63 [==============================] - 5s 81ms/step - loss: 0.1665 - accuracy: 0.9260 - val_loss: 1.7126 - val_accuracy: 0.6027
def plot_history(history):
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
plot_history(history)
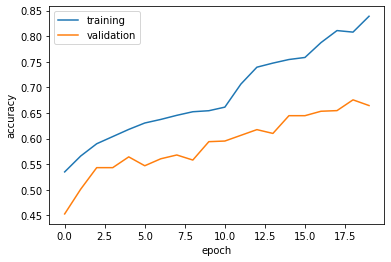
Our first model had a 60% accuracy and throughout training it went from as low as 54% to as high as 61%! This is a solid 10% greater than our baseline model. Looking at our visualization we can also see a fair amount of overfitting as well.
Creating our second model
Now lets augment our data in this second model. Augmenting our data means we include modified copies of the same image in the training set. For example a flipped picture of a cat is still a cat! First we’ll be adding in flipped images to our training data, then rotated images.
#randomly flips
flip = tf.keras.Sequential([
layers.RandomFlip()
])
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(4):
ax = plt.subplot(2, 2, i + 1)
flipped = flip(tf.expand_dims(first_image, 0))
plt.imshow(flipped[0] / 255)
plt.axis('off')

#this fills in empty space with the nearest pixel
rotate = tf.keras.Sequential([
layers.RandomRotation(0.5,fill_mode = 'nearest')
])
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(4):
ax = plt.subplot(2, 2, i + 1)
rotated = rotate(tf.expand_dims(first_image, 0))
plt.imshow(rotated[0] / 255)
plt.axis('off')

Now onto our second model itself.
model2 = models.Sequential([
layers.RandomFlip(input_shape = (160,160,3)),
layers.RandomRotation(factor = .5, fill_mode = 'nearest'),
layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Dropout(0.2),
layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Dropout(0.2),
layers.Conv2D(filters = 64, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Flatten(),
layers.Dense(64, activation = 'relu'),
layers.Dense(2)
])
model2.compile(loss=losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=['accuracy'])
history = model2.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 7s 90ms/step - loss: 14.6296 - accuracy: 0.5070 - val_loss: 0.6977 - val_accuracy: 0.5074
Epoch 2/20
63/63 [==============================] - 5s 82ms/step - loss: 0.7072 - accuracy: 0.5035 - val_loss: 0.6932 - val_accuracy: 0.5173
Epoch 3/20
63/63 [==============================] - 5s 82ms/step - loss: 0.6896 - accuracy: 0.5280 - val_loss: 0.6668 - val_accuracy: 0.5681
Epoch 4/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6820 - accuracy: 0.5540 - val_loss: 0.6741 - val_accuracy: 0.5322
Epoch 5/20
63/63 [==============================] - 5s 82ms/step - loss: 0.6819 - accuracy: 0.5385 - val_loss: 0.6946 - val_accuracy: 0.5396
Epoch 6/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6802 - accuracy: 0.5475 - val_loss: 0.7035 - val_accuracy: 0.5322
Epoch 7/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6728 - accuracy: 0.5475 - val_loss: 0.6955 - val_accuracy: 0.5483
Epoch 8/20
63/63 [==============================] - 6s 84ms/step - loss: 0.6773 - accuracy: 0.5500 - val_loss: 0.6581 - val_accuracy: 0.5705
Epoch 9/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6662 - accuracy: 0.5800 - val_loss: 0.6693 - val_accuracy: 0.5817
Epoch 10/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6658 - accuracy: 0.5790 - val_loss: 0.6632 - val_accuracy: 0.6176
Epoch 11/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6568 - accuracy: 0.5755 - val_loss: 0.6632 - val_accuracy: 0.5743
Epoch 12/20
63/63 [==============================] - 6s 84ms/step - loss: 0.6475 - accuracy: 0.5995 - val_loss: 0.7965 - val_accuracy: 0.5916
Epoch 13/20
63/63 [==============================] - 6s 84ms/step - loss: 0.6724 - accuracy: 0.5685 - val_loss: 0.6884 - val_accuracy: 0.6077
Epoch 14/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6600 - accuracy: 0.5855 - val_loss: 0.6467 - val_accuracy: 0.6089
Epoch 15/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6676 - accuracy: 0.5775 - val_loss: 0.6593 - val_accuracy: 0.5965
Epoch 16/20
63/63 [==============================] - 5s 82ms/step - loss: 0.6665 - accuracy: 0.6030 - val_loss: 0.6719 - val_accuracy: 0.5854
Epoch 17/20
63/63 [==============================] - 5s 82ms/step - loss: 0.6588 - accuracy: 0.6110 - val_loss: 0.6663 - val_accuracy: 0.6002
Epoch 18/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6459 - accuracy: 0.6375 - val_loss: 0.6385 - val_accuracy: 0.6324
Epoch 19/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6385 - accuracy: 0.6240 - val_loss: 0.6336 - val_accuracy: 0.6300
Epoch 20/20
63/63 [==============================] - 6s 84ms/step - loss: 0.6374 - accuracy: 0.6290 - val_loss: 0.6190 - val_accuracy: 0.6634
plot_history(history)
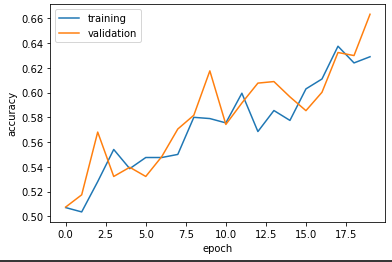
In our second model we now have 66% validation accuracy, throughout training it went from 50% to 66%. This is about 6% higher than model one. There also appears to be some slight overfitting in this model, but not as much as model one.
Creating our third model
Lets add a Preprocessing layer to our model which will tranform our data. Originally our data has RGB values from 0 to 255. By normalizing these values from 0 to 1 or -1 to 1 beforehand we spend more of our training energy handling actual signal in our data. The following code block will be how our Preprocessing layer looks like:
i = tf.keras.Input(shape=(160, 160, 3))
x = tf.keras.applications.mobilenet_v2.preprocess_input(i)
preprocessor = tf.keras.Model(inputs = [i], outputs = [x])
Now onto our model:
model3 = models.Sequential([
preprocessor,
layers.RandomFlip(),
layers.RandomRotation(factor = .2),
layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', input_shape = (160,160,3)),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Dropout(0.2),
layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Dropout(0.2),
layers.Conv2D(filters = 64, kernel_size = (3,3), activation = 'relu'),
layers.MaxPooling2D(pool_size = (2,2)),
layers.Flatten(),
layers.Dense(64, activation = 'relu'),
layers.Dense(2)
])
model3.compile(loss=losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=['accuracy'])
history = model3.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 7s 86ms/step - loss: 0.7806 - accuracy: 0.4935 - val_loss: 0.6924 - val_accuracy: 0.5780
Epoch 2/20
63/63 [==============================] - 6s 84ms/step - loss: 0.6885 - accuracy: 0.5335 - val_loss: 0.6727 - val_accuracy: 0.6002
Epoch 3/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6670 - accuracy: 0.5715 - val_loss: 0.6594 - val_accuracy: 0.5594
Epoch 4/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6565 - accuracy: 0.5810 - val_loss: 0.6403 - val_accuracy: 0.6089
Epoch 5/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6438 - accuracy: 0.6050 - val_loss: 0.6478 - val_accuracy: 0.5829
Epoch 6/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6587 - accuracy: 0.5830 - val_loss: 0.6427 - val_accuracy: 0.5990
Epoch 7/20
63/63 [==============================] - 6s 85ms/step - loss: 0.6382 - accuracy: 0.6175 - val_loss: 0.6404 - val_accuracy: 0.6361
Epoch 8/20
63/63 [==============================] - 6s 83ms/step - loss: 0.6241 - accuracy: 0.6365 - val_loss: 0.6343 - val_accuracy: 0.6337
Epoch 9/20
63/63 [==============================] - 5s 83ms/step - loss: 0.6119 - accuracy: 0.6555 - val_loss: 0.6001 - val_accuracy: 0.6671
Epoch 10/20
63/63 [==============================] - 6s 83ms/step - loss: 0.5938 - accuracy: 0.6800 - val_loss: 0.5958 - val_accuracy: 0.6559
Epoch 11/20
63/63 [==============================] - 6s 84ms/step - loss: 0.5983 - accuracy: 0.6685 - val_loss: 0.6025 - val_accuracy: 0.6720
Epoch 12/20
63/63 [==============================] - 6s 85ms/step - loss: 0.5897 - accuracy: 0.6795 - val_loss: 0.5945 - val_accuracy: 0.6869
Epoch 13/20
63/63 [==============================] - 6s 83ms/step - loss: 0.5670 - accuracy: 0.6955 - val_loss: 0.5844 - val_accuracy: 0.6832
Epoch 14/20
63/63 [==============================] - 6s 84ms/step - loss: 0.5622 - accuracy: 0.7035 - val_loss: 0.5667 - val_accuracy: 0.6931
Epoch 15/20
63/63 [==============================] - 6s 85ms/step - loss: 0.5522 - accuracy: 0.7240 - val_loss: 0.5600 - val_accuracy: 0.7153
Epoch 16/20
63/63 [==============================] - 6s 84ms/step - loss: 0.5510 - accuracy: 0.7195 - val_loss: 0.5609 - val_accuracy: 0.6980
Epoch 17/20
63/63 [==============================] - 6s 85ms/step - loss: 0.5457 - accuracy: 0.7295 - val_loss: 0.5503 - val_accuracy: 0.7067
Epoch 18/20
63/63 [==============================] - 6s 84ms/step - loss: 0.5359 - accuracy: 0.7285 - val_loss: 0.5570 - val_accuracy: 0.7178
Epoch 19/20
63/63 [==============================] - 6s 85ms/step - loss: 0.5236 - accuracy: 0.7410 - val_loss: 0.5792 - val_accuracy: 0.7129
Epoch 20/20
63/63 [==============================] - 6s 84ms/step - loss: 0.5289 - accuracy: 0.7375 - val_loss: 0.5704 - val_accuracy: 0.7191
plot_history(history)
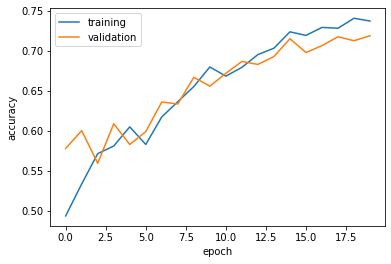
Our third model now has 71% validation accuracy and throughout training it went from 57% to 71%. This is 5% more than our second model. Looking at our plot there seems to be no overfitting on it which is definitely an improvement over models one and two.
Creating our fourth model
Lets try using a pre-existing model for our task of classifying dogs and cats. This is helpful since this pre-existing model may have picked up some relevant patterns to classification that our models that we built from scratch haven’t.
To access a pre-existing “base model” do the following:
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
base_model.trainable = False
i = tf.keras.Input(shape=IMG_SHAPE)
x = base_model(i, training = False)
base_model_layer = tf.keras.Model(inputs = [i], outputs = [x])
Now lets incorporate it into a full model and train it and look at the summary of it!
model4 = models.Sequential([
preprocessor,
layers.RandomFlip(),
layers.RandomRotation(factor = .2),
base_model_layer,
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(2)
])
model4.compile(loss=losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=['accuracy'])
model4.summary()
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model (Functional) (None, 160, 160, 3) 0
random_flip_7 (RandomFlip) (None, 160, 160, 3) 0
random_rotation_5 (RandomRo (None, 160, 160, 3) 0
tation)
model_1 (Functional) (None, 5, 5, 1280) 2257984
dropout_6 (Dropout) (None, 5, 5, 1280) 0
flatten_3 (Flatten) (None, 32000) 0
dense_6 (Dense) (None, 64) 2048064
dense_7 (Dense) (None, 2) 130
=================================================================
Total params: 4,306,178
Trainable params: 2,048,194
Non-trainable params: 2,257,984
_________________________________________________________________
history = model4.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 12s 120ms/step - loss: 0.4772 - accuracy: 0.8525 - val_loss: 0.0733 - val_accuracy: 0.9752
Epoch 2/20
63/63 [==============================] - 6s 91ms/step - loss: 0.2348 - accuracy: 0.8945 - val_loss: 0.0605 - val_accuracy: 0.9777
Epoch 3/20
63/63 [==============================] - 6s 92ms/step - loss: 0.1905 - accuracy: 0.9210 - val_loss: 0.0785 - val_accuracy: 0.9703
Epoch 4/20
63/63 [==============================] - 6s 91ms/step - loss: 0.1958 - accuracy: 0.9225 - val_loss: 0.0724 - val_accuracy: 0.9691
Epoch 5/20
63/63 [==============================] - 6s 92ms/step - loss: 0.1523 - accuracy: 0.9365 - val_loss: 0.0798 - val_accuracy: 0.9678
Epoch 6/20
63/63 [==============================] - 7s 103ms/step - loss: 0.1644 - accuracy: 0.9345 - val_loss: 0.0705 - val_accuracy: 0.9740
Epoch 7/20
63/63 [==============================] - 6s 92ms/step - loss: 0.1435 - accuracy: 0.9505 - val_loss: 0.0673 - val_accuracy: 0.9728
Epoch 8/20
63/63 [==============================] - 6s 91ms/step - loss: 0.1314 - accuracy: 0.9495 - val_loss: 0.0487 - val_accuracy: 0.9790
Epoch 9/20
63/63 [==============================] - 6s 92ms/step - loss: 0.1281 - accuracy: 0.9455 - val_loss: 0.0540 - val_accuracy: 0.9752
Epoch 10/20
63/63 [==============================] - 6s 91ms/step - loss: 0.1288 - accuracy: 0.9495 - val_loss: 0.0541 - val_accuracy: 0.9790
Epoch 11/20
63/63 [==============================] - 6s 91ms/step - loss: 0.1206 - accuracy: 0.9465 - val_loss: 0.0666 - val_accuracy: 0.9703
Epoch 12/20
63/63 [==============================] - 6s 90ms/step - loss: 0.1079 - accuracy: 0.9555 - val_loss: 0.0774 - val_accuracy: 0.9703
Epoch 13/20
63/63 [==============================] - 6s 92ms/step - loss: 0.0963 - accuracy: 0.9580 - val_loss: 0.0789 - val_accuracy: 0.9678
Epoch 14/20
63/63 [==============================] - 6s 92ms/step - loss: 0.1069 - accuracy: 0.9535 - val_loss: 0.0681 - val_accuracy: 0.9691
Epoch 15/20
63/63 [==============================] - 6s 90ms/step - loss: 0.0977 - accuracy: 0.9630 - val_loss: 0.0820 - val_accuracy: 0.9715
Epoch 16/20
63/63 [==============================] - 6s 91ms/step - loss: 0.1002 - accuracy: 0.9635 - val_loss: 0.0614 - val_accuracy: 0.9777
Epoch 17/20
63/63 [==============================] - 6s 91ms/step - loss: 0.0809 - accuracy: 0.9695 - val_loss: 0.0851 - val_accuracy: 0.9752
Epoch 18/20
63/63 [==============================] - 6s 91ms/step - loss: 0.0820 - accuracy: 0.9660 - val_loss: 0.0749 - val_accuracy: 0.9691
Epoch 19/20
63/63 [==============================] - 6s 93ms/step - loss: 0.0968 - accuracy: 0.9615 - val_loss: 0.0703 - val_accuracy: 0.9715
Epoch 20/20
63/63 [==============================] - 6s 91ms/step - loss: 0.0873 - accuracy: 0.9650 - val_loss: 0.0970 - val_accuracy: 0.9703
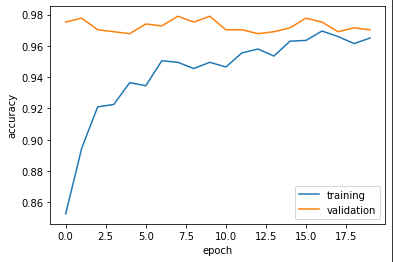
plot_history(history)
Looking at the summary of our fourth model we can see that we have to train about 2 million parameters.
The validation accuracy of our fourth model is 97%. Throughout training our model hovered between 96% and 97%. This is about 26% more than our third model and looking at the graph we do not see any overfitting.
Scoring on test data
Now lets finally evaluate the accuracy of fourth model on the unseen test_dataset to truly see how our model performs.
model4.evaluate(test_dataset)
6/6 [==============================] - 1s 63ms/step - loss: 0.0452 - accuracy: 0.9844
[0.04520997777581215, 0.984375]
The accuracy of our fourth model on the unseen test_dataset was 98%, which is really impressive!
Thank you for reading along. Hopefully you have learned a lot and can classify images of your own liking now!